Loading... 正则表达式是匹配模式,要么匹配字符,要么匹配位置。 本章内容包括: 1. 什么是位置? 2. 如何匹配位置? 3. 位置的特性 4. 几个应用实例案例 ##### 1. 什么是位置呢? 位置是相邻字符之间的位置。比如,下图中箭头所指的地方: 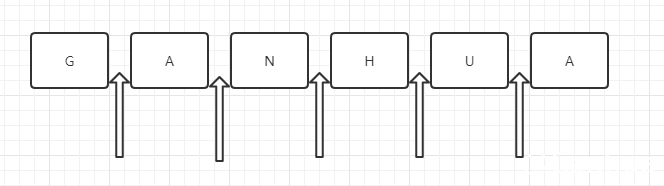 ##### 2. 如何匹配位置呢? ###### 2.1 ^和$ `^`(脱字符)匹配开头,在多行匹配中匹配行开头。 `$`(美元符号)匹配结尾,在多行匹配中匹配行结尾。 比如我们用#把字符串开头和结尾替换掉。 ```java String content = "hello"; System.out.println(content.replaceAll("^|$","#")); // => #hello# ``` 多行匹配模式时,二者是行的概念,这个需要我们的注意:注意/n /m /i 是javascript的相关概念。 ```javascript var result = "I\nlove\njavascript".replace(/^|$/gm, '#'); console.log(result); /* #I# #love# #javascript# */ ``` ###### 2.2 \b和\B `\b`是单词边界,具体就是`\w`和`\W`之间的位置,也包括`\w`和`^`之间的位置,也包括`\w`和`$`之间的位置。 比如一个文件名是"[JS] Lesson_01.mp4"中的`\b`,如下: ```java String content = "[JS] Lesson_01.mp4"; System.out.println(content.replaceAll("\\b","#")); // => [#JS#] #Lesson_01#.#mp4# ``` why?分析: 首先,我们知道,`\w`是字符组`[0-9a-zA-Z_]`的简写形式,即`\w`是字母数字或者下划线的中任何一个字符。而`\W`是排除字符组`[^0-9a-zA-Z_]`的简写形式,即`\W`是`\w`以外的任何一个字符。 此时我们可以看看"[#JS#] #Lesson_01#.#mp4#"中的每一个"#",是怎么来的。 * 第一个"#",两边是"["与"J",是`\W`和`\w`之间的位置。 * 第二个"#",两边是"S"与"]",也就是`\w`和`\W`之间的位置。 * 第三个"#",两边是空格与"L",也就是`\W`和`\w`之间的位置。 * 第四个"#",两边是"1"与".",也就是`\w`和`\W`之间的位置。 * 第五个"#",两边是"."与"m",也就是`\W`和`\w`之间的位置。 * 第六个"#",其对应的位置是结尾,但其前面的字符"4"是`\w`,即`\w`和`$`之间的位置。 知道了`\b`的概念后,那么`\B`也就相对好理解了。 `\B`就是`\b`的反面的意思,非单词边界。例如在字符串中所有位置中,扣掉`\b`,剩下的都是`\B`的。 具体说来就是`\w`与`\w`、`\W`与`\W`、`^`与`\W`,`\W`与`$`之间的位置。 比如上面的例子,把所有`\B`替换成"#": ```java String content = "[JS] Lesson_01.mp4"; System.out.println(content.replaceAll("\\B","#")); // => #[J#S]# L#e#s#s#o#n#_#0#1.m#p#4 ``` ###### 2.3 (?=p)和(?!p) `(?=p)`,其中`p`是一个子模式,即`p`前面的位置。 比如`(?=a)`,表示'a'字符前面的位置,例如: ```java String content = "ganhua"; System.out.println(content.replaceAll("(?=a)","#")); // => g#anhu#a ``` 而`(?!p)`就是`(?=p)`的反面意思,比如: ```java String content = "ganhua"; System.out.println(content.replaceAll("(?!a)","#")); // => #ga#n#h#ua# ``` 二者的学名分别是positive lookahead和negative lookahead。 还支持positive lookbehind和negative lookbehind。 具体是`(?<=p)`和`(?<!p)`。 也有书上把这四个东西,翻译成环视,即看看右边或看看左边。 但一般书上,没有很好强调这四者是个位置。 比如`(?=p)`,一般都理解成:要求接下来的字符与`p`匹配,但不能包括`p`的那些字符。 而在本人看来`(?=p)`就与`^`一样好理解,就是`p`前面的那个位置。 ```java String content = "ganhua"; System.out.println(content.replaceAll("(?<=a)","#")); // => ga#nhua# ``` ##### 3. 位置的特性 > 对于位置的理解,我们可以理解成空字符""。 比如"hello"字符串等价于如下的形式: ```java "hello" == "" + "h" + "" + "e" + "" + "l" + "" + "l" + "o" + ""; ``` 因此,把`/^hello$/`写成`/^^hello?$/`,是没有任何问题的: ```java String content = "hello"; String pattern = "^^hello?$"; List<String> resultFindAll = ReUtil.findAll(pattern, content, 0, new ArrayList<String>()); // => [hello] ``` 甚至还可以写成更复杂的: ```java String content = "hello"; String pattern = "(?=he)^^he(?=\\w)llo$\\b\\b$"; // => [hello] ``` 也就是说字符之间的位置,可以写成多个。 把位置理解空字符,是对位置非常有效的理解方式。 ##### 4. 相关案例 ###### 4.1 不匹配任何东西的正则 让你写个正则不匹配任何东西 `/.^/` 因为此正则要求只有一个字符,但该字符后面是开头。 ###### 4.2 数字的千位分隔符表示法 比如把"12345678",变成"12,345,678"。 可见是需要把相应的位置替换成","。 思路是什么呢? **4.2.1 弄出最后一个逗号** 使用`(?=\d{3}$)`就可以做到: ```java String content = "12345678"; String pattern = "(?=\\d{3}$)"; System.out.println(content.replaceAll(pattern, ",")); // => 12345,678 ``` **4.2.2 弄出所有的逗号** 因为逗号出现的位置,要求后面3个数字一组,也就是`\d{3}`至少出现一次。 此时可以使用量词`+`: ```java String content = "12345678"; String pattern = "(?=(\\d{3})+$)"; // => 12,345,678 ``` **4.2.3 匹配其余案例** 写完正则后,要多验证几个案例,此时我们会发现问题: ```java String content = "123456789"; String pattern = "(?=(\\d{3})+$)"; // => ,123,456,789 ``` 因为上面的正则,仅仅表示把从结尾向前数,一但是3的倍数,就把其前面的位置替换成逗号。因此才会出现这个问题。 怎么解决呢?我们要求匹配的到这个位置不能是开头。 我们知道匹配开头可以使用`^`,但要求这个位置不是开头怎么办? easy,`(?!^)` 测试如下: ```java String content = "123456789"; String pattern = "(?!^)(?=(\\d{3})+$)"; // => 123,456,789 ``` 最后修改:2021 年 10 月 20 日 © 来自互联网 打赏 赞赏作者 支付宝微信 赞 社会很单纯~复杂滴是人呐~谁能在乎我呀
